
Текстовая информация в компьютере, как и все другие виды информации, кодируется двоичными кодами. Каждому символу алфавита ставится в соответствие целое число, которое принято считать кодом этого символа.
В традиционных кодировках для кодирования одного символа используется последовательность из 8 нулей и единиц 8 бит = 1 байт .
Различных последовательностей из 8 нулей и единиц существует 256 (28=256). Поэтому такой 8-ми разрядный код позволяет закодировать 256 различных символов.
Присвоение символу определенного числового кода - это вопрос соглашения. В качестве международного стандарта принята таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для обмена информацией), кодирующая первую половину символов с числовыми кодами от 0 до 127 (коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII
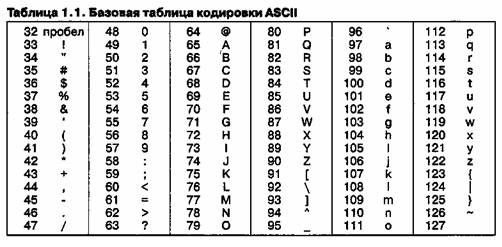
Для кодирования символов национальных алфавитов используется расширение кодовой таблицы ASCII, то есть 8-ми разрядные коды от 128 до 255.
Национальные стандарты кодировочных таблиц включают международную часть кодовой таблицы без изменений , а во второй содержат коды национальных алфавитов, символы псевдографики и некоторые математические знаки. В настоящее время существует 5 различных кодировок кириллицы (КОИ8, Windows. MSDOS, Macintosh, ISO), что вызывает определенные трудности при работе с рускоязычными документами.
В конце 90-х годов появился новый международный стандарт Unicode, который отводит под 1 символ не один байт, а два, поэтому с его помощью можно закодировать 65536 различных символов. Он включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Комментариев нет:
Отправить комментарий